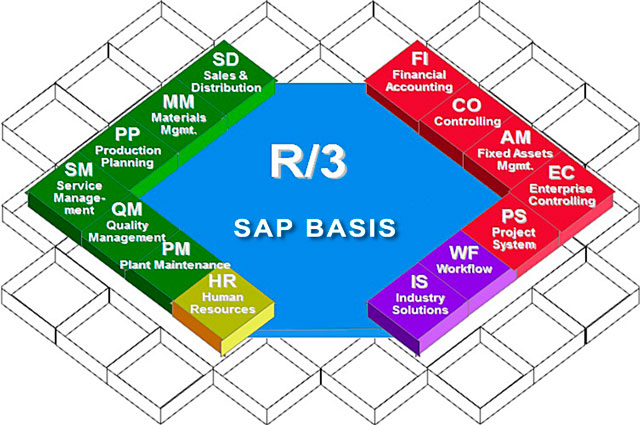
Я начал свою профессиональную деятельность в 2002 году. Почти сразу судьба свела меня с системами SAP, которые я с тех пор и администрирую. Как я начинал свою карьеру и попал в SAP, я описывал в
посте про своё 35-летие.
Проработав около 5 лет, я начал понимать, что мне стало тесно в роли SAP Basis консультанта. Захотелось передать свои знания, поделиться какими-то наработками и материалами.
Причин данного желания я вижу две.
Во-первых, желание передать другому свои знания у меня было всегда. Это как шило в одном месте. :) Я всегда восхищался людьми, которые могут буквально "на пальцах" объяснять сложные вещи. К тому же, во времена начала моей карьеры информации по администрированию систем SAP было очень мало, особенно на русском языке. Приходилось собирать её по крупицам, чуть ли не как легенды, которые один администратор передавал другому. Это еще при условии, что первый был готов и, самое главное, мог поделиться знаниями с ближним. Мне хотелось внести свой вклад в общее дело, отдать, так сказать, дань.
Во-вторых, администраторы в своей массе, как мне кажется, более замкнутые и скромные люди, чем, например, функциональные консультанты. Специфика работы у них такая: работают либо в одиночку, либо в очень тесном кругу. С пользователями общаться не имеют ни нужды, ни стремлений. А поделиться задумками, мыслями, обсудить проблему и пути решения хочется.
Поэтому в 2008 году я зарегистрировал
этот блог и написал свой
первый пост.
Мотивов написания статей и постов за это время было множество. Сначала, как я уже написал, было желание высказаться, поделиться чем-то. Например,
ощущениями от SAP семинара,
инструкциями по установке системы или
решением какой-то проблемы. Иногда, это был
ответ на чей-то вопрос или просьба осветить какой-то момент или тему. Был даже момент, когда я подумывал сменить сферу деятельности и выложить всё, что знал по администрированию, в блог. Но период прошёл, мотивация сменилась, сферу деятельности не поменял. :)
Не скрою, что одно время мною владела идея немного заработать на блоге, или как сейчас говорят "монетизировать блог". Статистика посещения моего блога на данный момент такова: по рабочим дням примерно 60 уникальных посетителей и 130-150 просмотров. Бывают пиковые значения 95 и 220 соответственно, но происходит это очень редко. В месяц получается около 6500 - 7500 просмотров, при хорошем раскладе (рис. 1). Статистику я никогда не скрывал, она отображается внизу правой колонки. Согласитесь, что посещение не ахти какое. Мой опыт показывает, что увеличение частоты написания постов дает небольшой прирост посещаемости (+10-15 %), но при этом быстро истощает мои нервные и физические силы.
 |
| Рис. 1. Статистика блога sidadm за последний месяц. |
Я повесил на свой блог два блока рекламы. Больше не вижу смысла, так как сам рекламу не люблю и использую "
AdBlock" во всех своих браузерах. Теперь, внимание! За примерно 6 лет показа этих блоков рекламы от Google я "заработал"
63,71 $ (рис. 2)! Причем, вывести можно сумму от 100 $. Таким образом, на рекламе я не заработал ни копейки. Ну и, честно говоря, эта затея почти сразу стала представлять для меня чисто спортивный интерес.
 |
| Рис. 2. Статистика Google AdSense. |
Конечно же, есть косвенный профит. Как вы знаете, я публикую свои статьи и посты не только у себя в блоге, но и с некоторого времени, на
портале SAPLand. И иногда я даже получаю за это кое-какие дивиденды. Например,
признание и славу журналы, книги по SAP или даже семинар (который пока только в планах). Но, конечно же, это всё несерьезно и непостоянно.
Я усвоил для себя мысль, что используя тематику "Администрирование систем SAP" и публикуя посты в одиночку, большую аудиторию не соберешь, а следовательно, на рекламе и подобных механизмах денег не заработаешь. Даже, ведя блог такое продолжительное время, как я. Признаюсь, это очень не просто. Блогов на тематику SAP, в которых 3-5 постов 4-5 летней давности в Интернете вагон и маленькая тележка.
Так что же мотивирует меня не бросать этот блог и продолжать писать? Информации сейчас в сети в разы больше, чем когда я начинал. В том числе и на русском языке. Можно далеко не ходить и взять для примера тот же портал
SAPLand или знаменитый
SAPForum.RU. Денег на ведении блога тоже не заработаешь. Так что же?
Ну, во-первых, меня мотивирует то, что данный ресурс содержит уже более 220 постов, и, как минимум, 60 % из них вполне актуальны и реально полезны. Бросить такой проект уже не так просто, как блог из 5 постов. К тому же у меня есть, хочется в это верить, постоянная аудитория, которая читает мой блог и изредка даёт об этом знать. Кстати, обратная связь тоже хороший мотивирующий фактор, и её никогда мало не бывает.
Во-вторых, и это главный аргумент, данный блог держит меня в тонусе. Писать по 3-5 постов в месяц - это комфортный для меня режим, при котором я могу выдавать качественный и полезный контент, а не посты по теме "проснулся, вошёл в систему, проверил логи, поел, пошел спать". :) Тот кто писал статьи или посты знает, что это далеко не так просто, как кажется на первый взгляд. Даже, если тема знакомая и простая, то при написании статьи необходимо собрать информацию из всех доступных источников и свести её воедино. Если есть пробелы в знаниях или хотя бы просто неуверенность в каких-то моментах, то необходимо найти все ответы и удостовериться в их точности. А про мало знакомую тему я и не говорю. Плюс для каждой статьи надо подготовить скриншоты, нарисовать пояснительные схемы. Поэтому для меня писать посты и статьи - это очень полезное занятие, которое обновляет мои собственные знания и при котором я более тщательно прорабатываю новые для себя темы. Существует такое утверждение, что человек лучше знает материал, если может объяснить его другому.
В-третьих, оформление информации и собственных мыслей в текстовом виде - это хороший навык, который пригодится при написании документации, справок или руководств на основной работе в качестве SAP Basis консультанта.
Если у вас есть хоть небольшое желание о чём-то написать, чем-то поделиться, оформить какие-то свои мысли, то обязательно попробуйте написать пост или статью. Не обязательно создавать свой собственный блог. Попробуйте опубликовать свою статью на существующем ресурсе. Например, на
SAPLand или любом другом. Поверьте, вам это даст очень много.
Если вам нужен будет совет или захотите что-то мне написать на эту тему, то мой адрес прежний - shibolov@gmail.com.
Автор:
Шиболов Вячеслав Анатольевич